ICML 2017,大体思路:卷积+一个线性门控单元,替代了传统的RNN进行language modeling,后来的Facebook将这个用于机器翻译,提出了卷积版的seq2seq模型。原文链接:Language Modeling with Gated Convolutional Networks
摘要
当前流行的语言建模模型是基于RNN的。在这类任务上的成功经常和他们捕捉unbound context有关。这篇文章中我们提出了一个通过堆叠convolutions的finite context方法,卷积可以变得更有效因为他们可以在序列上并行。我们提出了一个新型的简单的门控机制,这个门控机制表现的要比Oord et al.(2016b)要好,我们也探究了关键架构决策的影响。我们提出的方法在WikiText-103上达到了最好的效果,even though it features long-term dependencies,在Google Billion Words上也达到了最好的效果。Our model reduces the latency to score a sentece by an order of magnitude compared to a recurrent baseline. 据我们所知,这是在大规模语言任务上第一次一个非循环结构的方法超越了强有力的循环模型。
引言
统计语言模型估计一个单词序列的概率分布,通过给定当前的单词序列,对下一个单词的概率进行建模
$$P(w\_0, ..., w\_N) = P(w\_0)\prod^N\_{i=1}P(w\_i \mid w\_0, ..., w\_{i-1})$$其中$w_i$是单词表中的单词下标。语言模型对语音识别(Yu & Deng, 2014)和机器翻译(Koehn, 2010)来说是很重要的一部分。 最近,神经网络(Bengio et al., 2014; Mikolov et al., 2010; Jozefowicz et al., 2016)已经展示出了比传统n-gram模型(Kneser & Ney, 1995; Chen & Goodman, 1996)更好的语言模型。这些传统模型不能解决数据稀疏的问题,这个问题导致这些方法很难对大量的上下文进行表示,因此也不能回长范围的依赖进行表示。神经语言模型通过在连续空间中对词的嵌入解决了这个问题。当前最好的语言模型是基于LSTM(Hochreiter et al., 1997)的模型,LSTM理论上可以对任意长度的依赖进行建模。 在这篇文章中,我们引入了新的门控卷积网络,并且用它进行语言建模。卷积网络可以被堆叠起来来表示大量的上下文并且在越来越长的有着抽象特征(LeCun & Bengio, 1995)的上下文中提取层次特征。这使得这些模型可以通过上下文为$N$,卷积核宽度为$k$,$O(\frac{N}{k})$的操作对长时间的依赖关系进行建模。相反,循环网络将输入看作是一个链式结构,因此需要一个线性时间$O(N)$的操作。 层次的分析输入与传统的语法分析相似,传统的语法分析建立粒度增加的语法树结构,比如,包含名词短语和动词短语的句子,短语中又包含了更内在的结构(Manning & Schutze, 1999; Steedman, 2002)。层次结构也会让学习变得更简单,因为对于一个给定的上下文大小,相比链式结构,非线性单元的数量会减少,因此减轻了梯度消失的问题(Glorot & Bengio, 2010)。 现代的硬件对高度并行的模型支持的很好。在循环神经网络中,下一个输出依赖于之前的隐藏状态,而之前的隐藏状态在序列中元素上是不能并行的。然而,卷积神经网络对这个计算流程支持的很好因为卷积是可以在输入元素上同时进行的。 对于RNN来说想要达到很好的效果(Jozefowicz et al., 2016),门的作用很重要。我们的门控线性单元为深层的结构对梯度提供了一条线性的通道,同时又保留了非线性的特性,减少了梯度消失的现象。 我们展示了门控卷积网络比其他的已经发表的语言模型都要好,比如在Google Billion Word Benchmark(Chelba et al., 2013)上的LSTM。我们也评估了我们的模型在处理长范围依赖关系WikiText-103上的能力,在这个数据集上,模型是以段落为条件进行输入的,而不是一个句子,我们在这个数据集(Merity et al., 2016)上获得了最好的效果。最后,我们展示了门控线性单元获得了更好的精度以及相比于Oord et al., 2016的LSTM门收敛的更快。
方法
在这篇文章中我们引入了一种新的神经语言模型,这种模型使用门控时间卷积替代了使用在循环神经网络中使用的循环链接。神经语言模型(Bengio et al., 2003)提供了一种对每个单词$w_0, …, w_N$的上下文表示$H=[h_0, …, h_N]$用来预测下一个词的概率$P(w_i \mid h_i)$。循环神经网络$f$通过一个循环函数$h_i = f(h_{i-1}, w_{i-1})$计算$H$,这个循环函数本质上是一种不能并行处理的序列操作。
我们提出的方法使用函数$f$对输入进行卷积来获得$H = f \ast w$并且因此没有时间上的依赖,所以它能更好的在句子中的单词上并行计算。这个过程将会把许多前面出现的单词作为一个函数进行计算。对比卷积神经网络,上下文的大小是有限的,但是我们展示出了有限的上下文大小不是必须的,而且我们的模型可以表示足够大的上下文并表现的很好。
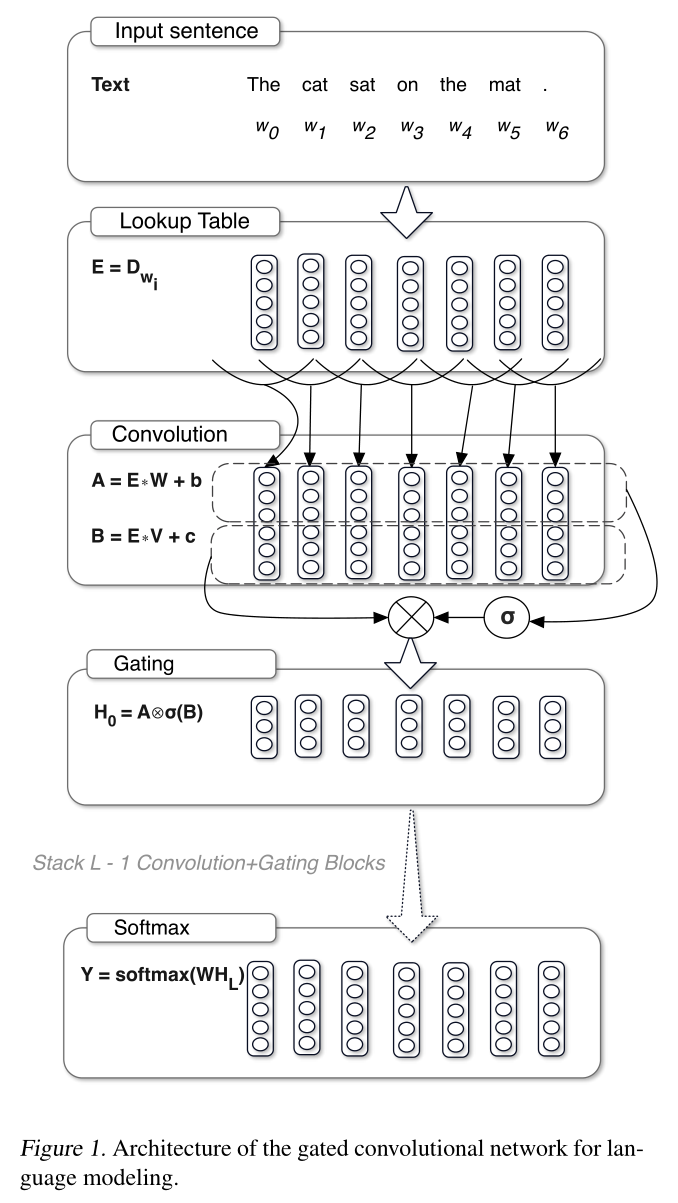 图1展示了模型的架构。词通过一个嵌入的向量进行表示,这些表示存储在lookup table$\mathbf{D}^{\vert \mathcal{V} \vert \times e}$中,其中$\vert \mathcal{V} \vert$是词库中单词的数量,$e$是嵌入的大小。我们模型的输入是一个词序列$w_0, …, w_N$,这个序列被词向量表示为$E = [D_{w_0}, …, D_{w_N}]$。我们将隐藏层$h_0, …, h_L$计算为
图1展示了模型的架构。词通过一个嵌入的向量进行表示,这些表示存储在lookup table$\mathbf{D}^{\vert \mathcal{V} \vert \times e}$中,其中$\vert \mathcal{V} \vert$是词库中单词的数量,$e$是嵌入的大小。我们模型的输入是一个词序列$w_0, …, w_N$,这个序列被词向量表示为$E = [D_{w_0}, …, D_{w_N}]$。我们将隐藏层$h_0, …, h_L$计算为
其中,$m$,$n$分别是输入和输出的feature map的数量,$k$是patch size,$X \in \mathbb{R}^{N \times m}$是层$h_l$的输入(要么是词嵌入,要么是前一层的输出),$W \in \mathbb{R}^{k \times m \times n}$,$b \in \mathbb{R}^n$,$V \in \mathbb{R}^{k \times m \times n}$,$c \in \mathbb{R}^n$是学习到的参数,$\sigma$是sigmoid function,$\otimes$是矩阵间的element-wise product。 当卷积输入时,我们注意$h_i$不包含未来单词的信息。我们通过移动卷积输入来防止卷积核看到未来的上下文(Oord et al., 2016a)来解决这个问题。特别地,我们在序列的开始加入了$k-1$宽度的0作为padding补全,假设第一个输入的元素是序列的开始元素,起始的标记我们是不预测的,$k$是卷积核的宽度。 每层的输出是一个线性变换$X \ast W + b$通过门$\sigma(X \ast W + b)$调节。与LSTM相似的是,这些门乘以矩阵的每个元素$X \ast W + b$,并且以层次的形式控制信息的通过。我们称这种门控机制为Gated Linear Units(GLU)。通过在输入$E$上堆叠多个这样的层,可以得到每个词$H = h_L \circ … \circ h_0(E)$的上下文表示。我们将卷积和门控线性单元放在了一个preactivation residual block,这个块将输入与输出相加(He et al., 2015a)。这个块有个bottleneck结构,可以使计算更高效并且每个块有5层。 获得模型预测结果最简单的是使用softmax层,但是这个选择对于语料库很大和近似来说一般计算起来很慢,像noise contrastive estimation(Gutmann & Hyvarinen)或层次softmax(Morin & Bengio, 2005)一般更常用。我们选了后者的改良版adaptive softmax,这个算法将higher capacity分配给出现频率更高的单词,lower capacity分配给频率低的单词(Grave et al., 2016a)。这使得在训练和测试的时候内存占用更少且计算速度更快。
门控机制
门控机制控制了网络中信息流通的路径,在循环神经网络中已经证明了是非常有效的手段(Hochreiter & Schumidhuber, 1997)。LSTM通过输入和遗忘门控制分离的细胞使得LSTM获得长时间的记忆。这使得信息可以不受阻碍的流通多个时间步。没有这些门,信息会在通过时间步的转移时轻易地消失。与之相比,卷积神经网络不会遇到这样的梯度消失现象,我们通过实验发现卷积神经网络不需要遗忘门。 因此,我们认为模型只需要输出门,这个门可以控制信息是否应该通过这些层。我们展示了这个模型对语言建模很有效,因为它可以使模型选择预测下一个单词的时候哪个单词是相关的。和我们同时进行研究的,Oord et al.(2016b)展示了LSTM风格的门控机制,$tanh(X \ast W + b) \otimes \sigma(X \ast V + c)$在对图像进行卷积建模的有效性。后来,Kalchbrenner et al. (2016)在翻译和字符级别的语言建模上使用额外的门扩展了这个机制。 门控线性单元是一种简化的门控机制,基于Dauphin & Grangier(2015)对non-deterministic gates的研究,这个门可以通过和门组合在一起的线性单元减少梯度消失的问题。这个门尽管允许梯度通过线性单元进行传播而不发生缩放的变化,但保持了层非线性的性质。我们称之为gated tanh unit(GTU)的LSTM风格的门的梯度是:
$$\nabla[tanh(X) \otimes \sigma(X)]=tanh'(X) \nabla X \otimes \sigma(X) + \sigma'(X) \nabla X \otimes tanh(X)$$注意到随着我们堆叠的层数的增加,它会渐渐地消失,因为$tanh’(X)$和$\sigma’(X)$这两个因数的数值范围在减小。相对来说,门控线性单元的梯度:
$$\nabla [X \otimes \sigma(X)] = \nabla X \otimes \sigma(X) + X \otimes \sigma'(X) \nabla X$$有一条路径$\nabla X \otimes \sigma(X)$对于在$\sigma(X)$中的激活的门控单元没有减小的因数。这可以被理解为一个跳过乘法的连接帮助梯度传播过这些层。我们通过实验比较了不同的门策略后发现门控线性单元可以收敛地更快且困惑度的值更好。