ACL 2018,基于LSTM+CRF,用word2vec对字符进行表示,然后用大规模自动分词的预料,将词进行表示,扔进LSTM获得细胞状态,与基于字符的LSTM的细胞状态相结合,得到序列的隐藏状态,然后套一个CRF。原文链接:Chinese NER Using Lattice LSTM
摘要
我们调查了lattice-structured LSTM模型在中文分词上的表现,这个模型将输入的字符序列和所有可能匹配到词典中的词进行编码。对比基于字符的方法,我们的模型明显的利用了词与词序列的信息。对于基于词的方法,lattice LSTM不会受到错误分词的影响。门控循环细胞可以使模型从序列中选取最相关的字符和单词获得更好的NER结果。实验在各种数据集上都显示出lattice LSTM比基于词和基于字的LSTM要好,获得了最好的效果。
引言
信息抽取中最基础的任务,NER近些年受到了广泛的关注。NER以往被当作一个序列标注问题来解决,实体的边界和类别标签是同时进行预测的。当前最先进的英文命名实体识别的方法是使用集成进单词表示的字符信息的LSTM-CRF模型(Lample et al., 2016; Ma and Hovy, 2016; Chiu and Nichols, 2016; Liu et al., 2018)。
中文NER与分词联系的很紧密。尤其是命名实体的边界也是词的边界。一个直观的想法是先分词,再标注词。然而这个pipeline会受到错误分词的影响,因为命名实体是分词中OOV中的很重要的一部分,而且不正确的实体边界划分会导致错误的NER。这个问题在open domain中很严重,因为跨领域的分词还是为解决的问题(Liu and Zhang, 2012; Jiang et al., 2013; Liu et al., 2014; Qiu and Zhang, 2015; Chen et al., 2017; Huang et al., 2017)。基于字符的方法比基于词的方法在中文NER中表现的好(He and Wang, 2008; Liu et al., 2010; Li et al., 2014)。
然而,基于字符的NER的一个缺点是,词与词的序列信息不能被完全利用到,然而这部分信息可能很有用。为了解决这个问题,我们通过使用一个lattice LSTM表示句子中的lexicon words,在基于字符的LSTM-CRF模型中集成了latent word information。如图1所示,我们通过使用一个大型的自动获取的词典来匹配一个句子,构建了一个词-字lattice。结果是,词序列,像“长江大桥”,“长江”,“大桥”可以用来在上下文中区分潜在的相关的命名实体,比如人名“江大桥”。
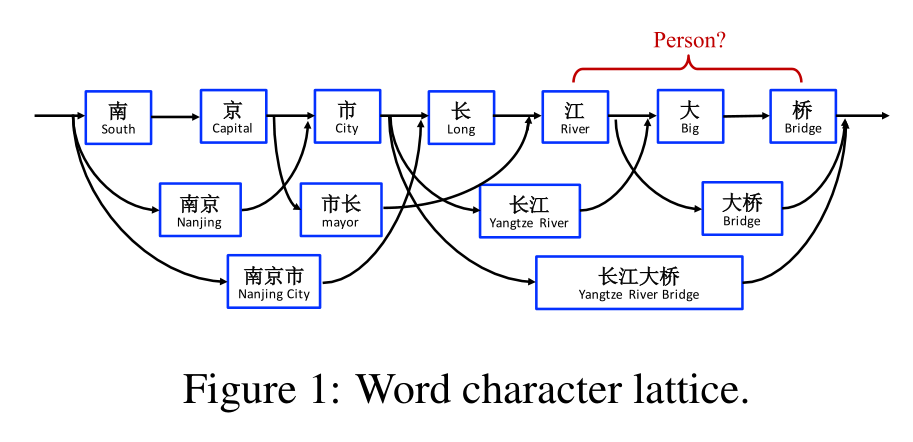
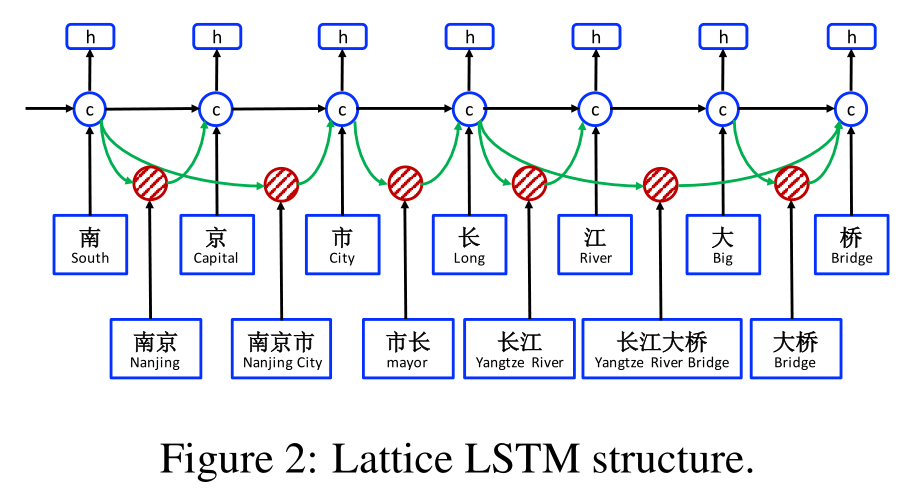 因为在lattice中有很多潜在的词-字路径,我们利用了一个lattice-LSTM结构来自动地控制句子的开始到结尾的信息流。如图2所示,门控细胞被用于动态规划信息从不同的路径到每个字符上。在NER数据上训练的lattice LSTM可以学习到如何从上下文中找到有用的单词,自动地提高NER的精度。对比基于字符的和基于单词的NER方法,我们的模型的优势在于利用在字符序列标签上的单词信息,且不会受到错误分词的影响。
结果显示我们的模型比字符序列标注模型和使用LSTM-CRF的单词序列标注模型都要好很多,在很多中文跨领域的NER数据集上都获得了很好的结果。我们的模型和数据在https://github.com/jiesutd/LatticeLSTM。
因为在lattice中有很多潜在的词-字路径,我们利用了一个lattice-LSTM结构来自动地控制句子的开始到结尾的信息流。如图2所示,门控细胞被用于动态规划信息从不同的路径到每个字符上。在NER数据上训练的lattice LSTM可以学习到如何从上下文中找到有用的单词,自动地提高NER的精度。对比基于字符的和基于单词的NER方法,我们的模型的优势在于利用在字符序列标签上的单词信息,且不会受到错误分词的影响。
结果显示我们的模型比字符序列标注模型和使用LSTM-CRF的单词序列标注模型都要好很多,在很多中文跨领域的NER数据集上都获得了很好的结果。我们的模型和数据在https://github.com/jiesutd/LatticeLSTM。
相关工作
我们的工作与当前处理NER的神经网络一致。Hammerton(2003)尝试解决使用一个单向的LSTM解决这个问题,这个第一个处理NER的神经网络。Collobert et al. (2011)使用了一个CNN-CRF的结构,获得了和最好的统计模型相当的结果。dos Santos et al. (2015)使用了字符CNN来增强CNN-CRF模型。大部分最近的工作利用了LSTM-CRF架构。Huang et al. (2015)使用手工的拼写特征;Ma和Hovy(2016)以及Chiu and Nichols(2016)使用了一个字符CNN来表示拼写的字符;Lample et al.(2016)使用一个字符LSTM,没有使用CNN。我们的baseline基于词的系统使用了与这些相似的架构。 字符序列标注是处理中文NER的主要方法(Chen et al., 2006b; Lu et al., 2016; Dong et al., 2016)。已经有讨论基于词的和基于字符的方法的统计的方法对比,表明了后者一般有更好的表现(He and Wang, 2008; Liu et al., 2010; Li et al., 2014)。我们发现有着恰当的表示设定,结论同样适用于神经NER。另一方面,lattice LSTM相比于词LSTM和字符LSTM是更好的一个选择。 如何更好的利用词的信息在中文NER任务中受到了持续的关注(Gao et al., 2015),分词信息在NER任务中作为soft features(Zhao and Kit, 2008; Peng and Dredze, 2015; He and Sun, 2017a),使用对偶分解的分词与NER联合学习也被人研究了(Xu et al., 2014),多任务学习(Peng and Dredze, 2016)等等。我们的工作也是,聚焦于神经表示学习。尽管上述的方法可能会被分词训练数据和分词的错误影响,我们的方法不需要一个分词器。这个模型不需要考虑多任务设定,因此从概念上来看就更简单。 NER可以利用外部信息。特别地,词典特征已经被广泛地使用了(Collobert et al., 2011; Passos et al., 2014; Huang et al., 2015; Luo et al., 2015)。Rei(2017)使用了一个词级别的语言模型目的是增强NER的训练,在大量原始语料上实现多任务学习。Peters et al.(2017)预训练了一个字符语言模型来增强词的表示。Yang et al.(2017b)通过多任务学习探索了跨领域和跨语言的知识。我们通过在大量自动分词的文本上预训练文本嵌入词典利用了外部信息,尽管半监督技术如语言模型are orthogonal to而且也可以在我们的lattice LSTM模型中使用。 Lattice结构的RNN可以被看作是一个树状结构的RNN(Tai et al., 2015)对DAG的自然扩展。他们已经有被用来建模运动力学(Sun et al., 2017),dependency-discourse DAGs(Peng et al., 2017),还有speech tokenization lattice(Sperber et al., 2017)以及对NMT(neural machine translation)编码器的多粒度分词输出。对比现在的工作,我们的lattice LSTM在动机和结构上都是不同的。比如,对于以字符为中心的lattice-LSTM-CRF序列标注设计的模型,它有循环细胞但是没有针对词的隐藏向量。据我们所知,我们第一个设计了一个新型的lattice LSTM对字母和词进行混合的表示,也是第一个使用一个基于词的lattice处理不分词的中文NER任务的。
模型
我们跟从最好的英语NER模型(Huang et al., 2015; Ma and Hovy, 2016; Lample et al., 2016),使用LSTM-CRF作为主要的网络结构。使用$s=c_1, c_2, …, c_m$表示输入的句子,其中$c_j$表示第$j$个字符。$s$可以被看作一个单词序列$s=w_1, w_2, …, w_n$,其中$w_i$表示序列中的第$i$个单词,由一个中文分词器获得。我们使用$t(i, k)$表示句子中第$i$个单词的第$k$个字符表示下标$j$。取图1的句子作为例子。如果分词结果是“南京市 长江大桥”,下标从1开始,那么$t(2, 1)=4$(长),$t(1, 3)=3$(市)。我们使用BIOES标记(Ratinov and Roth, 2009)对基于词和基于字的NER进行标记。
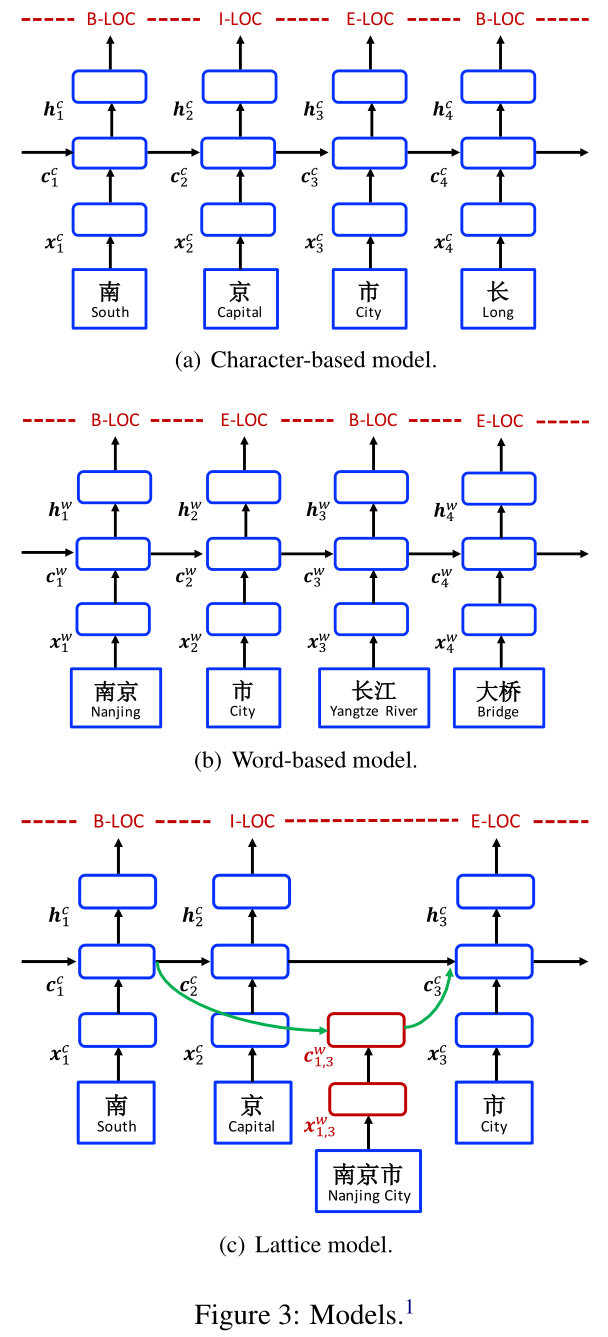
基于字符的模型
基于字符的模型如图3(a)所示。它在$c_1, c_2, …, c_m$上使用了LSTM-CRF模型。每个字符$c_j$表示为
$$x^c\_j = e^c(c\_j)$$其中$e^c$表示一个字符嵌入到了lookup table中。 一个双向LSTM(与式11同结构)被使用在$x_1, x_2, …, x_m$来获取从左到右的$\overrightarrow{h}^c_1, \overrightarrow{h}^c_2, …, \overrightarrow{h}^c_m$和从右到左的$\overleftarrow{h}^c_1, \overleftarrow{h}^c_2, …, \overleftarrow{h}^c_m$隐藏状态,这两个隐藏状态有两组不同的参数。每个字符的隐藏向量表示为
$$h^c\_j = [\overrightarrow{h}^c\_j, \overleftarrow{h}^c\_j]$$一个标准的CRF模型被用在$h^c_1, h^c_2, …, h^c_m$上来进行序列标注。
- 字符+双字符 Character bigrams在分词中用来表示字符已经很有用了(Chen et al., 2015; Yang et al., 2017a)。我们提出了通过拼接双元字符嵌入和字符嵌入的基于字符的模型: $$x^c\_j = [e^c(c\_j); e^b(c\_j, c\_{j+1})]$$ 其中$e^b$表示一个character bigram lookup table。
- 字符+softword 已经有实验表明使用分词作为soft features对于基于字符的NER模型可以提升性能(Zhao and Kit, 2008; Peng and Dredze, 2016)。我们提出的通过拼接分词标记嵌入和字符嵌入的带有分词信息的字符表示: $$x^c\_j = [e^c(c\_j); e^s(seg(c\_j))]$$ 其中$e^s$表示一个分词标签嵌入查询表。$seg(c_j)$表示一个分词器在字符$c_j$上给出的分词标签。我们使用了BMES策略来表示分词(Xue, 2003) $$h^w\_i = [\overrightarrow{h^w\_i}, \overleftarrow{h^w\_i}]$$ 与基于字符的情况类似,一个标准的CRF模型在序列标记中被用在了$h^w_1, h^w_2, …, h^w_m$上。
基于词的模型
基于词的模型如图3(b)所示,它将word embedding $e^w(w_i)$作为每个词$w_i$的表示:
$$x^w\_i = e^w(w\_i)$$其中$e^w$表示一个词嵌入查找表。一个双向LSTM被用来获取词序列$w_1, w_2, …, w_n$上一个从左到右的隐藏状态$\overrightarrow{h}^w_1, \overrightarrow{h}^w_2, …, \overrightarrow{h}^w_n$和一个从右到左的隐藏状态序列$\overleftarrow{h}^w_1, \overleftarrow{h}^w_2, …, \overleftarrow{h}^w_n$。最后,对于每个词$w_i$,$\overrightarrow{h^w_i}$和$\overleftarrow{h^w_i}$会被拼在一起成为它的表示: 集成字符表示 字符CNN(Ma and Hovy, 2016)和LSTM(Lample et al., 2016)两种方法都被用于过表示一个单词中的字符序列。我们在中文NER中对两个方法都进行了实验。我们使用$x^c_i$表示$w_i$中的字符,通过拼接$e^w(w_i)$和$x^c_i$可以获得一个新词的表示:
$$x^w\_i = [e^w(w\_i; x^c\_i)]$$- 词+字符LSTM 将每个输入字符的嵌入记作$e^c(c_j)$,我们使用一个双向LSTM来学习词$w_i$的字符$c_{t(i, 1)}, …, c_{t(i, len(i))}$的隐藏状态$\overrightarrow{h}^c_{t(i, 1)}, …, \overrightarrow{h}^c_{t(i, len(i))}$和$\overleftarrow{h}^c_{t(i, 1)}, …, \overleftarrow{h}^c_{t(i, len(i))}$,其中$len(i)$表示词$w_i$的字符个数。最后$w_i$的字符表示为: $$x^c\_i = [\overrightarrow{h}^c\_{t(i, len(i))};\overleftarrow{h}^c\_{t(i, 1)}]$$
- 词+字符LSTM' 我们调查了一种词+字符LSTM的变形,这个模型使用单向的LSTM对每个字符获取$\overrightarrow{h}^c_j$和$\overleftarrow{h}^c_j$。与Liu et al. (2018)的结构相似但是没有使用highway layer。使用了相同的LSTM结构和相同的方法集成字符隐藏状态进词嵌入中。
- 词+字符CNN 我们使用标准的CNN(LeCun et al., 1989)应用在词的字符序列上获得字符表示$x^c_i$。将字符$c_j$的嵌入记为$e^c(c_j)$,向量$x^c_i$通过以下式子得到: $$x^c\_i = \max\_{t(i,1) \leq j \leq t(i, len(i))}(W^T\_{CNN} \begin{bmatrix} e^c(c\_{j-\frac{ke-1}{2}}) \\ ... \\ e^c(c\_{j+\frac{ke-1}{2}}) \end{bmatrix}+ b\_{CNN})$$ 其中,$W_{CNN}$和$b_{CNN}$和参数,$ke=3$是核的大小,$max$表示最大池化。
Lattice模型
图2中展示了词-字lattice模型的整个结构,可以看作是基于字的模型的扩展,集成了基于词的细胞和用来控制信息流的额外的门。 图3(c)展示了模型的输入是一个字符序列$c_1, c_2, …, c_m$,与之一起的还有所有字符序列,字符都能在词典$\mathbb{D}$中匹配到。如部分2中指示的,我们使用自动分词的大型原始语料来构建$\mathbb{D}$。使用$w^d_{b,e}$来表示一个起始字符下标为$b$,结尾字符下标为$e$,图1中的$w^d_{1,2}$是“南京(Nanjing)”,$w^d_{7,8}$是“大桥(Bridge)”。 模型涉及到了四种类型的向量,分别是输入向量、输出隐藏向量、细胞向量、门向量。作为基本的组成部分,一个字符输入向量被用来表示每个字符$c_j$,就像在基于字符的模型中: $x^c_j = e^c(c_j)$ 基本的循环结构是通过一个在每个字符$c_j$上的字符细胞向量$\mathbf{c}^c_j$和一个隐藏向量$\mathbf{h}^c_j$构造的,其中$\mathbf{c}^c_j$提供句子的开始到$c_j$的信息流,$\mathbf{h}^c_j$用于CRF序列标注。 基础的循环LSTM函数如下:
$$ \begin{bmatrix} i^c\_j \\ o^c\_j \\ f^c\_j \\ \widetilde{c}^c\_j \end{bmatrix} = \begin{bmatrix} \sigma \\ \sigma \\ \sigma \\ tanh \end{bmatrix}({W^c}^T \begin{bmatrix} x^c\_j \\ h^c\_{j-1} \end{bmatrix}+b^c) $$$$c^c\_j = f^c\_j \odot c^c\_{j-1} + i^c\_j \odot \hat{c}^c\_j$$$$h^c\_j = o^c\_j \odot tanh(c^c\_j)$$其中,$i^c_j$,$f^c_j$和$o^c_j$表示一组输入、遗忘和输出门。${w^c}^T$和$b^c$是模型参数。$\sigma()$表示sigmoid function。 不同于基于字符的模型,现在计算$c^c_j$的时候需要考虑句子中词典序列$w^d_{b,e}$。特别地,每个序列$w^d_{b,e}$被表示为:
$$x^w\_{b,e} = e^w(w^d\_{b,e})$$其中$e^w$表示3.2节相同的词嵌入查询表。 此外,一个词细胞$c^w_{b,e}$用来表示$x^w_{b,e}$从句子开始的循环状态。$c^w_{b,e}$通过以下式子计算得到:
$$ \begin{bmatrix} i^w\_{b,e} \\ f^w\_{b,e} \\ \widetilde{c}^w\_{b,e} \end{bmatrix} = \begin{bmatrix} \sigma \\ \sigma \\ tanh \end{bmatrix}({w^w}^T \begin{bmatrix} x^w\_{b,e} \\ h^c\_b \end{bmatrix} + b^w) $$$$c^w\_{b,e} = f^w\_{b,e} \odot c^c\_b + i^w\_{b,e} \odot \widetilde{c}^w\_{b,e}$$其中$i^w_{b,e}$和$f^w_{b,e}$是一组输入和遗忘门。对于词细v胞来说没有输出门因为标记只在字符层面上做。 有了$c^w_{b,e}$,会有很多路径可以使信息流向每个$c^c_j$。比如,在图2中,对于$c^c_7$的输入包含$x^c_7$(桥Bridge),$c^w_{6,7}$(大桥Bridge)和$c^w_{4,7}$(长江大桥Yangtze River Bridge)。我们将$c^w_{b,e}$和$b \in \lbrace b’ \mid w^d_{b’,e} \in \mathbb{D}\rbrace$连接到细胞$c^c_e$。我们使用额外的门$i^c_{b,e}$对每个序列细胞$c^w_{b,e}$来控制它对$c^c_{b,e}$的贡献:
$$i^c\_{b,e} = \sigma({w^l}^T \begin{bmatrix} x^c\_e \\ c^w\_{b,e} \end{bmatrix} + b^l)$$因此,$c^c_j$的计算变为:
$$c^c\_j = \sum\_{b \in \lbrace b' \mid w^d\_{b',j} \in \mathbb{D}\rbrace } \alpha^c\_{b,j} \odot c^w\_{b,j} + \alpha^c\_j \odot \widetilde{c}^c\_j$$在上式中,门$i^c_{b,j}$和$i^c_{j}$的值被归一化到$\alpha^c_{b,j}$和$\alpha^c_j$,和为1。
$$ \alpha^c\_{b,j} = \frac{exp(i^c\_{b,j})}{exp(i^c\_j)+\sum\_{b' \in \lbrace b'' \mid w^d\_{b'',j} \in \mathbb{D}\rbrace}exp(i^c\_{b',j})} $$$$ \alpha^c\_{j} = \frac{exp(i^c\_{j})}{exp(i^c\_j)+\sum\_{b' \in \lbrace b'' \mid w^d\_{b'',j} \in \mathbb{D}\rbrace}exp(i^c\_{b',j})} $$最后的隐藏向量$h^c_j$仍然由之前的LSTM计算公式得到。在NER训练过程中,损失值反向传播到参数$w^c, b^c, w^w, b^w, w^l$和$b^l$使得模型可以动态地在NER标注过程中关注更相关的词。
解码和训练
一个标准的CRF层被用在$h_1, h_2, …, h_{\tau}$上面,其中$\tau$对于基于字符的模型来说是$n$,对于基于词的模型来说是$m$。一个标签序列$y = l_1, l_2, …, l_{\tau}$的概率是
$$ p(y \mid s) = \frac{exp(\sum\_i(w^{l\_i}\_{CRF} h\_i + b^{(l\_{i-1}, l\_i)}\_{CRF}))}{\sum\_{y'}exp(\sum\_i(w^{l'\_i}\_{CRF} h\_i + b^{(l'\_{i-1}, l'\_i)}\_{CRF}))} $$这里$y’$表示一个任意标签序列,$W^{l_i}_{CRF}$是针对于$l_i$的模型参数,$b^{(l_{i-1},l_i)}_{CRF}$是针对$l_{i-1}$和$l_i$的偏置。 我们使用一阶维特比算法来寻找一个基于词或基于字符的输入序列中得分最高的标签序列。给定一组手动标注的训练数据$\lbrace (s_i, y_i)\rbrace \mid^N_{i=1}$,带有L2正则项的句子层面的log-likelihood作为loss,训练模型:
$$L = \sum^N\_{i=1} log(P(y\_i \mid s\_i)) + \frac{\lambda}{2}\Vert \Theta \Vert^2$$其中,$\lambda$是L2正则项系数,$\Theta$表示了参数集合。