ICLR 2017(reject),两个模型,第一个是将数据扔到Defferrard的图卷积里面,然后将输出扔到LSTM里面。第二个模型是将RNN中的矩阵乘法换成了图卷积操作,最后对动态的mnist进行了识别。原文链接:Structured Sequence Modeling With Graph Convolutional Recurrent Networks
摘要
GCRN(Graph Convolutional Recurrent Network),一个可以预测结构化序列数据的深度学习模型。GCRN是传统的循环神经网络的在任意的图结构上的一种泛化形式。这样的结构化数据可以表示成视频中的一系列帧,检测器组成的网络监测到的时空监测值,或是用于自然语言建模的词网中的随机游走。我们提出的模型合并了图上的CNN来辨识空间结构,RNN寻找动态模型。我们研究了两种GCRN,对Penn Treebank数据集进行建模。实验显示同时挖掘图的空间与动态信息可以同时提升precision和学习速度。
1 Introduction
很多工作,Donahue et al. 2015; Karpathy & Fei-Fei 2015; Vinyals et al. 2015,利用CNN和RNN的组合来挖掘时空规律性。这些模型那个处理时间变化的视觉输入来做变长的预测。这些网络架构由视觉特征提取的CNN,和一个在CNN后面,用于序列学习的RNN组成。这样的架构成功地用于视频活动识别,图像注释生成以及视频描述。
最近,大家开始对时空序列建模时融合CNN和RNN感兴趣。受到语言模型的启发,Ranzato et al. 2014提出了通过发现时空相关性的能表示复杂变形和动作模式的模型。他们的实验表明在通过quantizing the image patches获得到的visual words上,使用RNN建模,可以很好的预测视频的下一帧以及中间帧。他们的表现最好的模型是recursive CNN(rCNN),对输入和状态同时使用卷积。Shi et al. 2015之后提出了卷积LSTM(convLSTM),一个使用2D卷积利用输入数据的空间相关性,用于时空序列建模的RNN模型。他们成功的对降雨临近预报的雷达回波图的演化进行了预测。
很多重要问题中,空间结构不是简单的网格状。气象站就不是网格状。而且空间结构不一定是空间上的,如社交网络或生物网络。最后,Mikolov et al. 2013等人认为,句子可以解释成在词网上的随机游走,使得我们转向了分析图结构的句子建模问题。
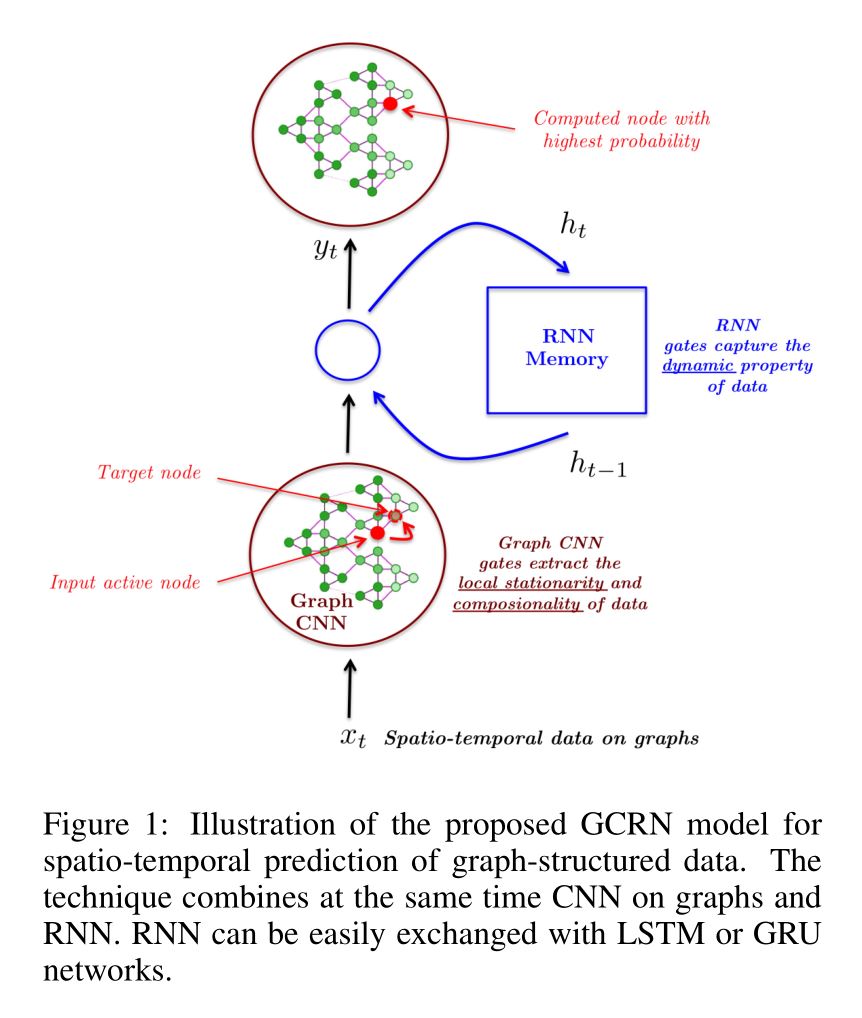
我们的工作利用了近期的模型——Defferrard et al. 2016; Ranzato et al. 2014; Shi et al. 2015——来设计GCRN模型对时间变化的图结构数据建模和预测。核心思想是融合图结构上的CNN和RNN来同时辨识空间结构和动态模式。图1给出了GCRN的架构。
2 Preliminaries
2.1 Structured Sequence Modeling
序列建模是给定前$J$个观测值,对未来最可能的长度为$K$的序列进行预测:
$$\tag{1} \hat{x}\_{t+1},...,\hat{x}\_{t+K} = \mathop{\mathrm{argmax}}\limits\_{x\_{t+1},...,x\_{t+K}}P(x\_{t+1},...,x\_{t+K} \mid x\_{t-J+1},...,x\_t), $$$x_t \in \mathbf{D}$是时间$t$的观测值,$\mathbf{D}$表示观测到的特征的域。原型应用是$n-\mathrm{gram}$模型$(n = J + 1)$,$P(x_{t+1} \mid x_{t-J+1},…,x_t)$对在句子中给定过去$J$个词时$x_{t+1}$出现的概率进行建模。
我们感兴趣的是特别的结构化的句子,也就是句子中$x_t$的特征不是相互独立的,而是有着两两相连的关系。这样的关系广义上通过带权图建模。
$x_t$可以看作是一个图信号,也就是一个定义在无向带权图$\mathcal{G} = ( \mathcal{V}, \Large{\varepsilon}, \normalsize{A )}$,其中$\mathcal{V}$是$\vert \mathcal{V} \vert = n$个顶点的有限集,$\Large{\varepsilon}$是边集,$A \in \mathbb{R}^{n \times n}$是带权邻接矩阵,编码了两个顶点之间的连接权重。定义在图的顶点上的信号$x_t: \mathcal{V} \rightarrow \mathbb{R}^{d_x}$可以当作是一个矩阵$x_t \in \mathbb{R}^{n \times d_x}$,列$i$是$d_x$维向量,表示$x_t$在第$i$个顶点的值。尽管自由变量的数量在长度为$K$的结构化序列中本质上是$\mathcal{O}(n^K{d_x}^K)$,我们仍然试图去挖掘可能的预测结果的空间结构以减少维度,来使这些问题变得容易解决。
2.2 Long Short-Term Memory
防止梯度过快消失,由Hochreiter & Schmidhuber 1997发明的一种RNN,LSTM。这个模型已经被证明在各种序列建模任务中,对长期依赖关系是稳定且强劲的模型(Graves, 2013; Srivastava et al., 2015; Sutskever et al., 2014)。全连接LSTM(FC-LSTM)可以看作是一个多变量版本的LSTM,其中$x_t \in \mathbb{R}^d_x$是输入,$h_t \in [-1, 1]^{d_h}$是细胞状态,$c_t \in \mathbb{R}^{d_h}$是隐藏状态,他们都是向量。我们使用Graves 2013的FC-LSTM:
$$\tag{2} i = \sigma(W\_{xi} x\_t + W\_{hi}h\_{t-1} + w\_{ci} \odot c\_{t-1} + b\_i),\\ f = \sigma(W\_{xf} x\_t + W\_{hf} h\_{t-1} + w\_{cf} \odot c\_{t-1} + b\_f),\\ c\_t = f\_t \odot c\_{t-1} + i\_t \odot \mathrm{tanh}(W\_{xc} x\_t + W\_{hc} h\_{t-1} + b\_c),\\ o = \sigma(W\_{xo} x\_t + W\_{ho} h\_{t-1} + w\_{co} \odot c\_t + b\_o),\\ h\_t = o \odot \mathrm{tanh}(c\_t), $$其中$\odot$表示Hadamard product,$\sigma(\cdot)$表示sigmoid function $\sigma(x) = 1/(1+e^{-x})$,$i,f,o \in [0, 1]^{d_h}$是输入门,遗忘门,输出门。权重$W_{x\cdot} \in \mathbb{R}^{d_h \times d_x}$,$W_{h\cdot} \in \mathbb{R}^{d_h \times d_h}$,$w_{c\cdot} \in \mathbb{R}^{d_h}$,偏置$b_i,b_f,b_c,b_o \in \mathbb{R}^{d_h}$是模型参数。这个模型之所以称为全连接是因为$W_{x\cdot}$和$W_{h\cdot}$与$x$和$h$所有分量进行线性组合。由Gers & Schmidhuber 2000引入可选的peephole connections $w_{c\cdot} \odot c_t$,在某些特定任务上可以提升性能。
2.3 Convolutional Neural Networks On Graphs
Defferrard et al., 2016选择了谱上的卷积操作:
$$\tag{3} y = g\_\theta \ast\_\mathcal{G} x = g\_\theta (L)x = g\_\theta (U \Lambda U^T)x = U g\_\theta (\Lambda) U^T x \in \mathbb{R}^{n \times d\_x}, $$对于归一化的拉普拉斯矩阵$L = I_n - D^{-1/2} A D^{-1/2} = U \Lambda U^T \in \mathbb{R}^{n \times n}$来说,$U \in \mathbb{R}^{n \times n}$是矩阵的特征向量,$\Lambda \in \mathbb{R}^{n \times n}$是特征值的对角矩阵。式3的时间复杂度很高,因为$U$的乘法的时间复杂度是$\mathcal{O}(n^2)$。此外,计算$L$的特征值分解对于大的图来说很慢。Defferrard et al., 2016使用切比雪夫多项式:
$$\tag{4} g\_\theta(\Lambda) = \sum^{K-1}\_{k=0} \theta\_k T\_k(\tilde{\Lambda}), $$参数$\theta \in \mathbb{R}^K$是切比雪夫系数的向量,$T_k(\tilde{\Lambda}) \in \mathbb{R}^{n \times n}$是切比雪夫多项式的k阶项在$\tilde{\Lambda} = 2\Lambda/\lambda_{max} - I_n$的值。图卷积操作可以写为:
$$\tag{5} y = g\_\theta \ast\_{\mathcal{G}} x = g\_\theta (L) x = \sum^{K-1}\_{k=0} \theta\_k T\_k (\tilde{L})x, $$$T_0 = 1$,$T_1 = x$,$T_k(x) = 2xT_{k-1}(x)-T_{k-2}(x)$,时间复杂度是$\mathcal{O}(K \vert \Large{\varepsilon} \normalsize \vert)$,也就是和边数相关。这个图卷积是$K$阶局部化的。
3 Related Works
Shi et al. 2015提出了针对常规网格结构的序列的模型,可以看作是图是图像网格且顶点有序的特殊情况。他们的模型本质上是FC-LSTM,$W$的乘法替换为卷积核$W$:
$$\tag{6} i = \sigma(W\_{xi} \ast x\_t + W\_{hi} \ast h\_{t-1} + w\_{ci} \odot c\_{t-1} + b\_i),\\ f = \sigma(W\_{xf} \ast x\_t + W\_{hf} \ast h\_{t-1} + w\_{cf} \odot c\_{t-1} + b\_f),\\ c\_t = f\_t \odot c\_{t-1} + i\_t \odot \mathrm{tanh}(W\_{xc} \ast x\_t + W\_{hc} \ast h\_{t-1} + b\_c),\\ o = \sigma(W\_{xo} \ast x\_t + W\_{ho} \ast h\_{t-1} + w\_{co} \odot c\_t + b\_o),\\ h\_t = o \odot \mathrm{tanh}(c\_t), $$$\ast$表示一组卷积核的2D卷积。在他们的设定中$x_t \in \mathbb{R}^{n_r \times n_c \times d_x}$是一个动态系统中,时间$t$的$d_x$的观测值,这个动态系统建立在一个表示为$n_r$行$n_c$列的空间区域上。模型有着空间分布的隐藏核细胞状态,大小是$d_h$,由张量$c_t$体现,$h_t \in \mathbb{R}^{n_r \times n_c \times d_h}$。卷积核$W_{h\cdot} \in \mathbb{R}^{m \times m \times d_h \times d_h}$和$W_{x\cdot} \in \mathbb{R}^{m \times m \times d_h \times d_x}$的尺寸$m$决定了参数的数量,与网格大小$n_r \times n_c$无关。更早一点,Ranzato et al. 2014提出了相似的RNN变体,使用卷积层而不是全连接层。时间$t$的隐藏状态:
$$\tag{7} h\_t = \mathrm{tanh}(\sigma(W\_{x2} \ast \sigma(W\_{x1} \ast x\_t)) + \sigma(W\_h \ast h\_{t-1})), $$卷积核$W_h \in \mathbb{R}^{d_h \times d_h}$受限到$1 \times 1$的大小。
观察到自然语言表示出语法性质,自然的将词融入短语中,Tai et al. 2015提出了一个处理树结构的模型,每个LSTM可以获取他们的孩子的状态。他们在semantic relatedness and sentiment classification上获得了state-of-the-art的结果。Liang et al. 2016在之后提出了在图上的变体。他们复杂的网络结构在4个数据集上获得了semantic object parsing的state-of-the-art结果。这些模型中,状态通过一个可训练的权重矩阵的带权加和从邻居上聚集。然而这些权重并不在图上共享,否则需要对顶点排序,就像其他图卷积的空间定义一样。此外,他们的公式受限于当前顶点的一阶邻居,给其他的邻居相同的权重。
受到如人体动作和物体交互等时空任务的启发,Jain et al 2016提出了一个方法将时空图看作是一个富RNN的混合,本质上是将一个RNN连接到每个顶点与每条边上。同样的,通信受限于直接连接的顶点与边。
和我们的工作最相关的模型可能是Li et al 2015提出的模型,在program verification上表现出了最好的结果。尽管他们使用Scarselli et al. 2009提出的GNN,以迭代的步骤传播顶点的表示,直到收敛,我们使用的是Defferrard et al. 2016提出的GCN在顶点间扩散信息。尽管他们的动机和我们很不一样,这些模型的关联是使用$K$阶多项式定义的谱滤波器可以实现成一个$K$层的GNN。
4 Proposed GCRN Models
我们提出了两种GCRN架构
Model 1.
$$\tag{8} x^{\mathrm{CNN}}\_t = \mathrm{CNN}\_\mathcal{G}(x\_t)\\ i = \sigma(W\_{xi} x^{\mathrm{CNN}}\_t + W\_{hi}h\_{t-1} + w\_{ci} \odot c\_{t-1} + b\_i),\\ f = \sigma(W\_{xf} x^{\mathrm{CNN}}\_t + W\_{hf} h\_{t-1} + w\_{cf} \odot c\_{t-1} + b\_f),\\ c\_t = f\_t \odot c\_{t-1} + i\_t \odot \mathrm{tanh}(W\_{xc} x^{\mathrm{CNN}}\_t + W\_{hc} h\_{t-1} + b\_c),\\ o = \sigma(W\_{xo} x^{\mathrm{CNN}}\_t + W\_{ho} h\_{t-1} + w\_{co} \odot c\_t + b\_o),\\ h\_t = o \odot \mathrm{tanh}(c\_t). $$我们简单地写成$x^{\mathrm{CNN}}_t = W^{\mathrm{CNN}} \ast_\mathcal{G} x_t$,其中$W^{\mathrm{CNN}} \in \mathbb{R}^{K \times d_x \times d_x}$是切比雪夫系数。Peepholes由$w_{c\cdot} \in \mathbb{R}^{n \times d_h}$控制。这样的架构可能足以捕获数据的分布,通过挖掘局部静止性以及性质的组合性,还有动态属性。
Model 2.
$$\tag{9} i = \sigma(W\_{xi} \ast\_\mathcal{G} x\_t + W\_{hi} \ast\_\mathcal{G} h\_{t-1} + w\_{ci} \odot c\_{t-1} + b\_i),\\ f = \sigma(W\_{xf} \ast\_\mathcal{G} x\_t + W\_{hf} \ast\_\mathcal{G} h\_{t-1} + w\_{cf} \odot c\_{t-1} + b\_f),\\ c\_t = f\_t \odot c\_{t-1} + i\_t \odot \mathrm{tanh}(W\_{xc} \ast\_\mathcal{G} x\_t + W\_{hc} \ast\_\mathcal{G} h\_{t-1} + b\_c),\\ o = \sigma(W\_{xo} \ast\_\mathcal{G} x\_t + W\_{ho} \ast\_\mathcal{G} h\_{t-1} + w\_{co} \odot c\_t + b\_o),\\ h\_t = o \odot \mathrm{tanh}(c\_t), $$图卷积核是切比雪夫系数$W_{h\cdot} \in \mathbb{R}^{K \times d_h \times d_h}$,$W_{x\cdot} \in \mathbb{R}^{K \times d_h \times d_x}$决定了参数的数目,与顶点数$n$无关。 这种RNN和CNN的混合,不限于LSTM。普通的RNN $h_t = \mathrm{tanh}(W_x x_t + W_h h_{t-1})$可以写为:
$$\tag{10} h\_t = \mathrm{tanh}(W\_x \ast\_\mathcal{G} x\_t + W\_h \ast\_\mathcal{G} h\_{t-1}), $$GRU的版本可以写为:
$$\tag{11} z = \sigma(W\_{xz} \ast\_\mathcal{G} x\_t + W\_{hz} \ast\_\mathcal{G} h\_{t-1}),\\ r = \sigma(W\_{xr} \ast\_\mathcal{G} x\_t + W\_{hr} \ast\_\mathcal{G} h\_{t-1}),\\ \tilde{h} = \mathrm{tanh}(W\_{xh} \ast\_\mathcal{G} x\_t + W\_{hh} \ast\_\mathcal{G} (r \odot h\_{t-1})),\\ h\_t = z \odot h\_{t-1} + (1 - z) \odot \tilde{h}. $$5 Experiments
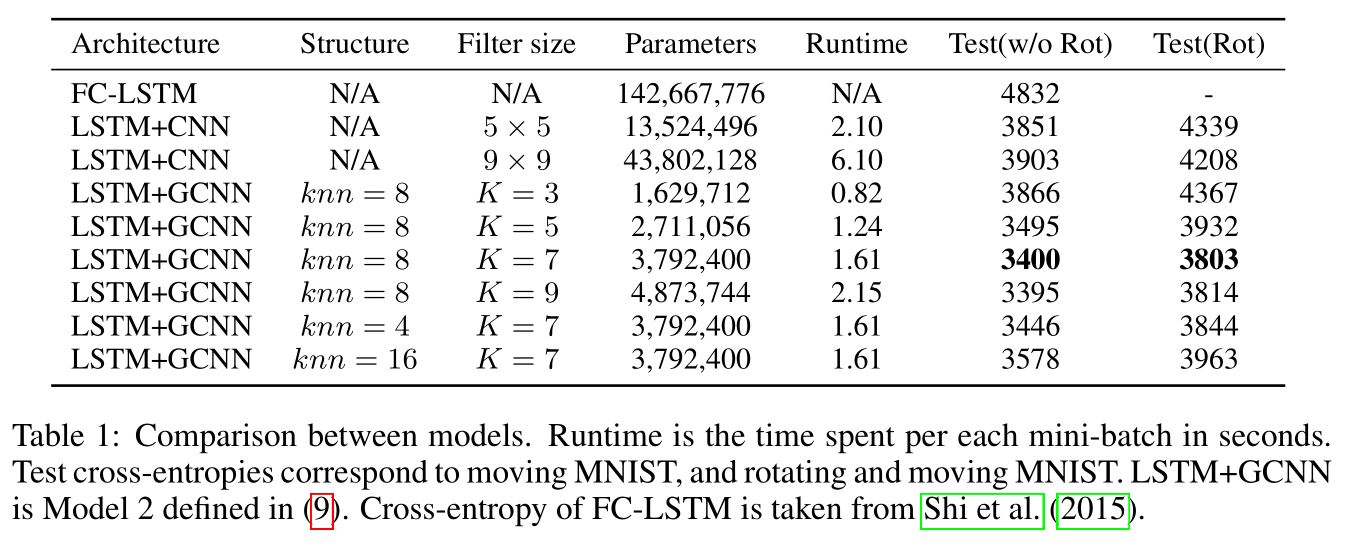
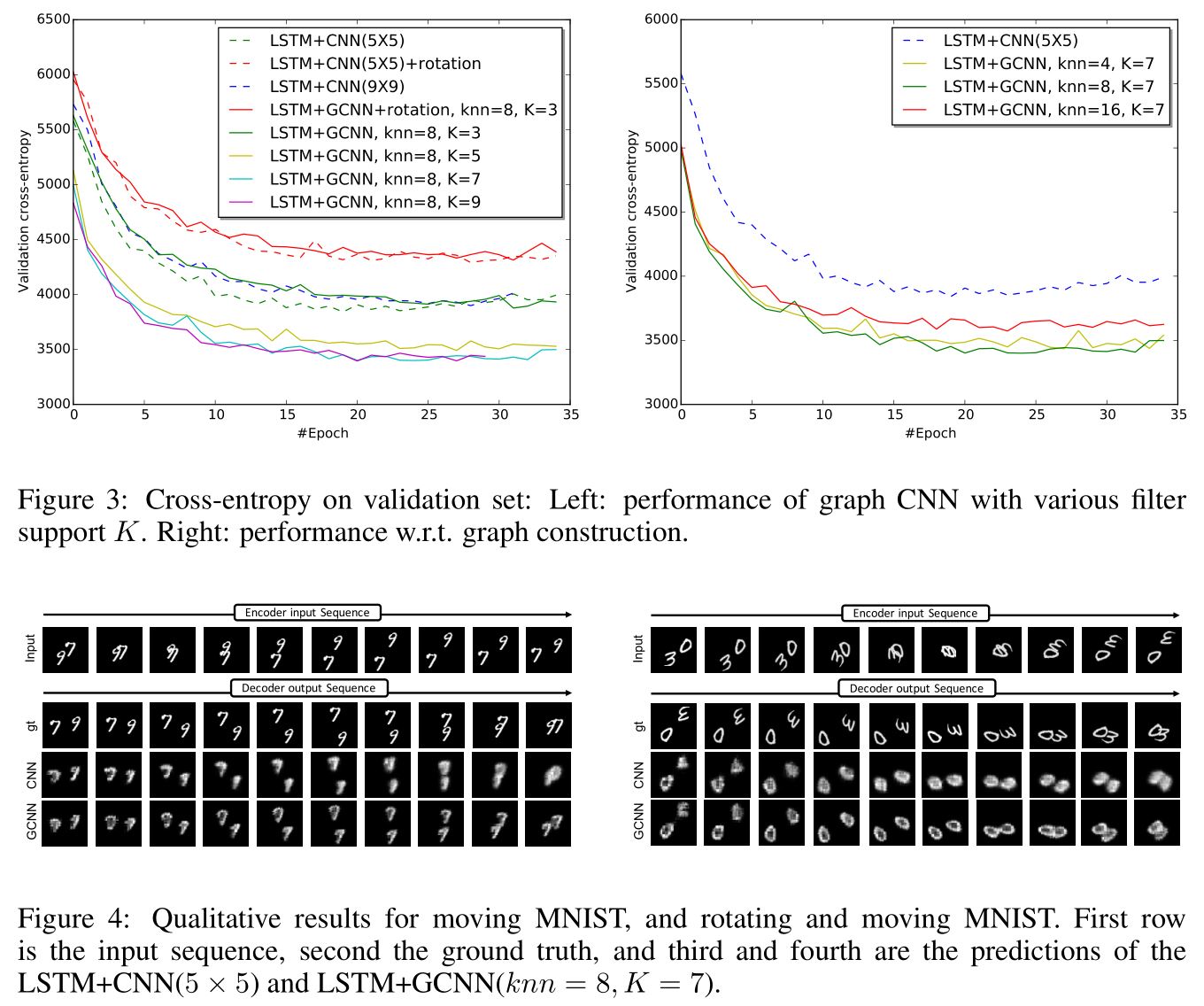
数据集是moving-MNIST(Shi et al., 2015)。